これは、FOLIO Advent Calendar 2023 の xx 日目の記事として投稿しようと思ったものです。。。。(忙しくて気がついたら 2 月になっていました)
今回は私がメンテナンスを引き継いだグラフを png 出力する AWS lambda の改善例を共有します。
背景
昨年の弊社のアドベントカレンダーに該当のリポジトリの紹介があるので、今回の記事では次のブログの内容を前提として内容を進めていきます。
この記事で紹介するコードは次になります。
このlambdaは json を s3 に put した場合それをトリガーし lambda を発火させ png 画像が生成させるものになります。
- s3 に put する json の例
[ { "label": "20代", "proportion": "0.15", "color": "#d53e4f" }, { "label": "30代", "proportion": "0.23", "color": "#fc8d59" }, { "label": "40代", "proportion": "0.21", "color": "#fee08b" }, { "label": "50代", "proportion": "0.18", "color": "#ffffbf" }, { "label": "60代", "proportion": "0.15", "color": "#e6f598" }, { "label": "70代以上", "proportion": "0.08", "color": "#99d594" } ]
- 出力されるグラフの例
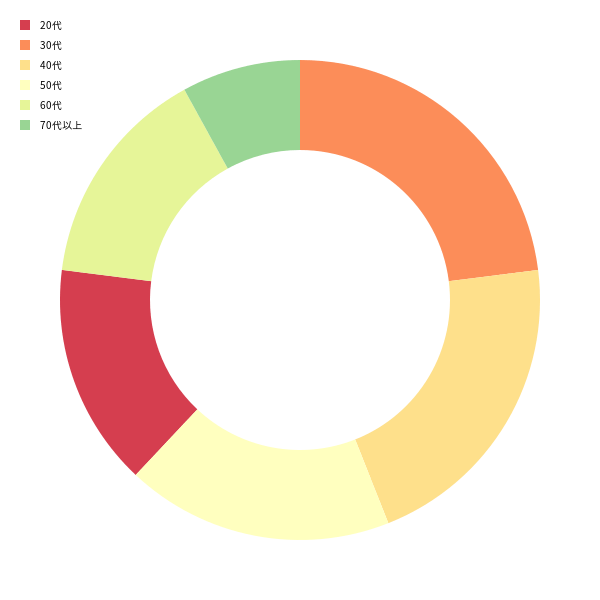
課題
このリポジトリの引き継ぎを受けた際に、node-canvas が jest と相性が悪く、描画関連の自動テストが一部整備できていないこと、またローカルで描画の動作確認ができない(毎回開発環境にデプロイしないと動作確認できない)という課題の共有がありました。
また、node-canvas というライブラリは内部的にネイティブライブラリを利用しているため、CI で TypeScript のトランスパイルは成功しても、lambda の実行時にエラーが発生することもあります。そのため、CI での lambda の実行テストも必要という話になりました。
つまりこのリポジトリを運用するにあたり、次の手段を確立する必要がありました。
- ローカルでグラフの表示の動作確認を行う手段
- ローカルおよび CI 環境で lambda を実行し、成果物の PNG ファイルを確認する手段
上記の課題を解決するために、開発環境改善のために Storybook の導入と、lambda の動作確認のために Docker で AWS Lambda と LocalStack の構築を行いました。
環境
- nodejs v16
- storybook v7.0.9
1. storybook(+webpack)の導入
UI カタログツール
storybook とは
storybook は web アプリケーションでページと UI コンポーネントを分離して、コンポーネントを独立した状態で開発できるようにする UI カタログツールです。
storybook for HTML とは
静的サイトを UI カタログとして管理できるものです。今回は lambda のグラフ生成部分(html element の段階)を UI コンポーネントとみなして storybook を利用します。 本来は html ファイルをカタログとして利用するプラグインですが、今回は html ファイルではなく、ts ファイル内の html element をカタログとして利用する方法を紹介します。
storybook の導入
現状のコードベースとして、esmodule と typescript が利用されています。しかし esmodule と typescript と今回追加したい webpack は相性が悪いという問題がありました。 これはwebpack の module の解決方法と esm の import の書き方が合わないのが原因です。issue にある次の対応を行い、module の解決を行えるように対応を行いました。
html element をカタログとして利用する方法
reander 関数が呼ばれた際に
という関数を渡すことで storybook でライフサイクルも含め UI カタログとして利用できるようになります
サンプルコードは以下になります
リファクタリング
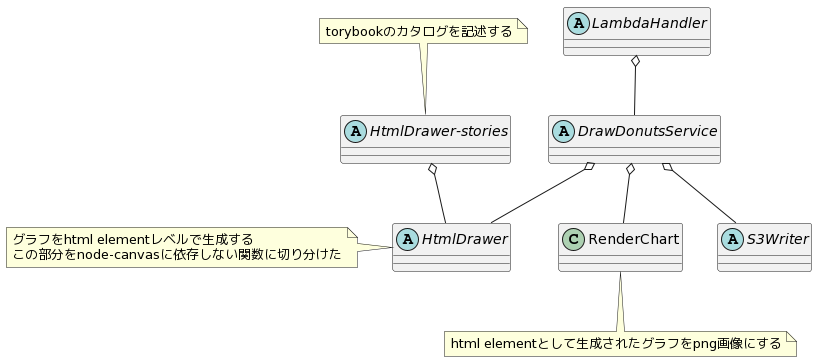
lambda では jsdom という Node.js 環境に HTML DOM API を追加するライブラリを利用しています。その DOM の canvas に node-canvas という Web Canvas API 互換のあるAPIを利用できるようにするライブラリを利用して グラフを描画しています。 しかし StoryBook(Webpack) はブラウザ上で動作するものなので Node.js でしか動作しない jsdom や node-canvas を利用している ts ファイルをそのまま利用することは出来ません。 グラフ生成部分を引数を渡すと element が返ってくる箇所を関数として切り出し、Node.js 上だと node-canvas、StoryBook だとグローバルな html element の子要素としてそれぞれ利用できるように修正を行いました。
※実際には module の top level に関数を定義しているため Abstract Classでは無いですがmoduleの依存関係のイメージはこのようになっています
また syorybook の text の欄にある json を編集するとグラフを再レンダリングするようにし、値によってグラフがどのように表示されるかもわかるようにしました。
実際の動作
実際に生成した storybook は以下になります。
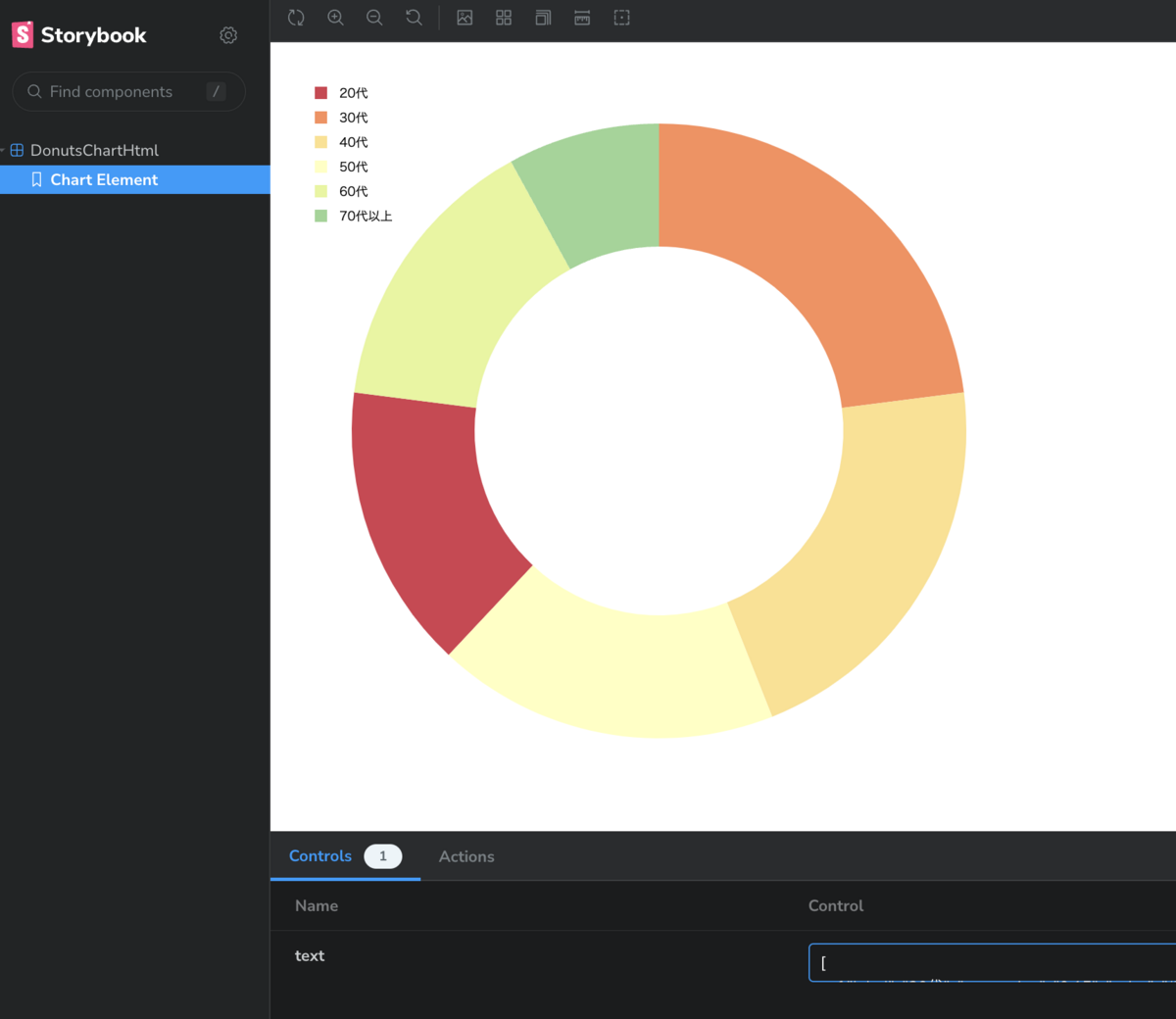
また GithubPages に deploy しているので是非 json の value を変えて、グラフが再描画される事を確認してみて下さい。業務ではもう少し複雑なグラフを生成しているので、エッジケースの確認などに便利に利用できます。
しかしこの改善を進めながら検証を進めた結果、jsdomと webpack(chromeで見ているので多分Blink?)は HTML のレンダリングエンジンが異なるため、storybook で表示されるものと実際に生成される PNG ファイルには細かいですが差分が存在する事がわかりました。そのため、storybook 上での表示内容を比較してのビジュアルリグレッションテストを行うことはできないという結論に至りました。
ローカルで chart の表示を確認できるようになり、開発はスムーズに行えるようになりました。しかし、ローカルでの表示内容が本番環境での表示内容と異なる場合、storybook の表示内容の差分を見て変更内容が正しいと判断できません。なので、lambda で生成される画像を確認する別の方法を確立する必要がありました。
2. local での lambda の動作確認
lambda が docker image で作成されているので local で lambda の docker container を起動し、同じく local で起動させた localstack の s3 に接続することで確認を行うことができます。
localstackのs3に接続する方法
localstack の s3 にアクセスするには path-style でアクセスするしかななく、path-style でアクセスするには S3Client のインスタンスを生成する際に forcePathStyle: true, を設定する必要があります。
new S3Client({ credentials: fromIni({ profile: "local" }), region: "ap-northeast-1", endpoint: "http://localstack:4566", forcePathStyle: true, });
また今回は s3 への put をトリガーにして lambda を発火させるわけではなく、s3 の put 時の notification event を lambda の引数にして lambda を実行します。今回は次の json を lambda の入力とします。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-s3.html
notification eventの例
{ "Records": [ { "eventVersion": "2.1", "eventSource": "aws:s3", "awsRegion": "us-east-2", "eventTime": "2019-09-03T19:37:27.192Z", "eventName": "ObjectCreated:Put", "userIdentity": { "principalId": "AWS:AIDAINPONIXQXHT3IKHL2" }, "requestParameters": { "sourceIPAddress": "205.255.255.255" }, "responseElements": { "x-amz-request-id": "D82B88E5F771F645", "x-amz-id-2": "vlR7PnpV2Ce81l0PRw6jlUpck7Jo5ZsQjryTjKlc5aLWGVHPZLj5NeC6qMa0emYBDXOo6QBU0Wo=" }, "s3": { "s3SchemaVersion": "1.0", "configurationId": "828aa6fc-f7b5-4305-8584-487c791949c1", "bucket": { "name": "local-bucket", "ownerIdentity": { "principalId": "A3I5XTEXAMAI3E" }, "arn": "arn:aws:s3:::lambda-artifacts-deafc19498e3f2df" }, "object": { "key": "graph/sample.json", "size": 1305107, "eTag": "b21b84d653bb07b05b1e6b33684dc11b", "sequencer": "0C0F6F405D6ED209E1" } } } ] }
実行方法
次の方法で動作を確認できます。
- lambda の docker を build する
- lambda と localstack の docker を起動する
- s3 の bucket を作成する
- json ファイルを s3 に入稿する
- lambda を実行する
- 実行結果生成された png ファイルを local にコピーする
具体的は次の script を実行します。
#!/bin/bash set -e LOCALSTACK_HOST="0.0.0.0" LOCALSTACK_PORT="4566" export AWS_ACCESS_KEY_ID=dummy export AWS_SECRET_ACCESS_KEY=dummy docker-compose build docker-compose up -d pwd sh ./setup/s3.sh # lambda で読み込む file を予め削除する echo "delete file" aws --region=ap-northeast-1 --endpoint-url="https://$LOCALSTACK_HOST:$LOCALSTACK_PORT" --no-verify-ssl s3 rm s3://local-bucket/graph--recursive # json file の入稿 echo "upload file" aws --region=ap-northeast-1 --endpoint-url="https://$LOCALSTACK_HOST:$LOCALSTACK_PORT" --no-verify-ssl --profile localstack s3 cp ./../sample/sample.json s3://local-bucket/graph/sample.json # lambda の実行 echo "running lambda" curl -XPOST http://localhost:9000/2015-03-31/functions/function/invocations -d @./test/sample_event_valid.json # png file のダウンロード aws --region=ap-northeast-1 --endpoint-url="https://$LOCALSTACK_HOST:$LOCALSTACK_PORT" --no-verify-ssl --profile localstack s3 cp s3://local-bucket/graph/sample.png ./sample.png open ./sample.png
改善を行ったことでできるようになったこと
改善を行った結果、ローカル環境でグラフ生成ロジックの確認や、Lambda を実行してグラフを簡単に確認できるようになりました。また、Lambda のリポジトリや Node.js に詳しくないメンバーでも、動作確認や修正が容易に行えるようになりました。
さらに、副次的な効果として、画像を簡単に生成できるようになったため、デザインチームとのコミュニケーション(細かい修正の検討など)が容易に行えるようになりました。さらに、グラフを Storybook で確認できるため、「デザイン仕様とグラフのロジックの生成結果が 1px ずれている」などの細かい差分も確認できるようになりました。
注意点
上記の localstack を利用した local での動作確認方法は nodejs 16 の image だと実行できるのですが nodejs18 だと実行できません。(node.js16 の EOL は 2023.09 なのでこの記事は賞味期限切れになる前に出したかったという事情があります。)
具体的には node-canvas が依存しているネイティブライブラリのバージョンが lambda/nodejs:18(amazonlinux2)とは合わず実行時エラーになります。node18 で利用するには ric を利用して custom image を作成する必要があります。
その他
引き継ぎドキュメントや実際の引き継ぎの際に現状の課題などを共有があり、実際の開発/運用方法がにわかったので当時と事情が変わった際にどのように改善を行うと効果的かがすぐわかりました。前任者の丁寧な仕事にとても感謝しています。
また去年のアドベントカレンダーに引き継ぎ前の状態を公開出来るように加工した記事とサンプルコードがあったのでこの記事もとても書きやすかったです。
まとめ
- AWS lambda で画像を生成するリポジトリに UI カタログを導入しました
- AWS lambda を local で動作確認できるように localstack などの docker 環境を構築しました
- 開発環境改善を行ったことで開発速度が向上しました